Introduction
What is Mapped?
Mapped is an AI powered data infrastructure platform for IoT, built to help customers securely access real-time data from building systems, sensors, enterprise applications and APIs. Through automation, we simplify the data discovery, extraction and normalization process, so you can easily access your data via our simple and secure API.
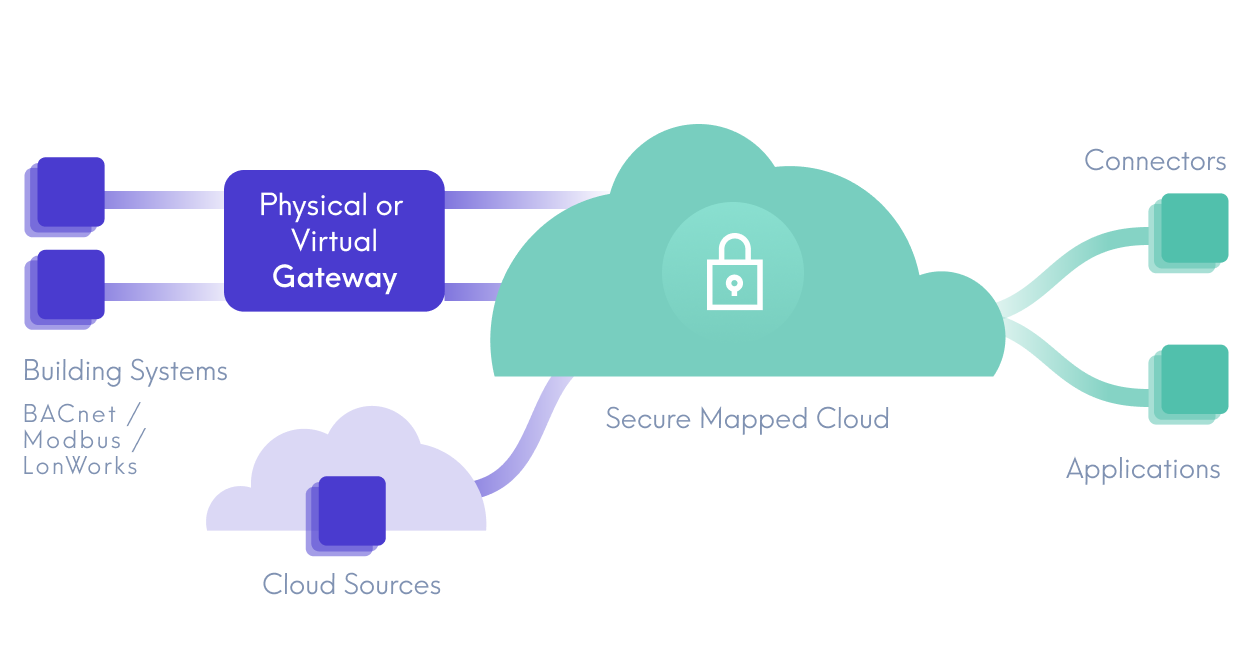
How it Works
Discovery
The Mapped Universal Gateway uses techniques typically found in cybersecurity appliances to actively scan IP-based networks, searching for in-building systems over a variety of protocols (e.g., BACnet, Modbus). The Gateway performs several different kinds of scans:
- Device discovery: Every seven days, the Gateway walks all IPs on the network. For each device that responds on the BACnet protocol, the Gateway performs a device scan.
- Device scan: Once a device or controller is discovered, the Gateway asks the device for all of its objects, at a default interval of 24 hours. For each object, it requests its points and all the point's properties, including additional information such as make, model, and firmware.
- Time series polling: For all discovered devices, objects, points and properties that are of time series type, Mapped Universal Gateway asks the device for the current value of each time series property, at a default interval of 60 seconds.
Extraction
The retrieved data is then packaged and securely transmitted over MQTT to the Mapped Cloud for processing and normalization. We employ numerous optimizations to reduce network overhead, including a binary serialization format, and an algorithm that only sends changes in point data (deltas) from the gateway to the cloud. Mapped can also extract data from third party Connectors via APIs.
Normalization
The data next travels through an analysis and transformation pipeline, eventually landing in one of our data stores. The stored data is aligned with the Mapped Graph ontology, which is an extension of Brick, an industry standard capable of modeling thousands of distinct system and point types. This normalized data is then available in the Mapped Console and the Mapped API for review and use.
Mapped Console
In the Mapped Console, you're able to see information about your onboarded locations via the Explore tab - buildings, floors, spaces. You have two options for the view - rendered into graphics you can interact with to see various details, all the way down to a specific device on a specific floor:
.png)
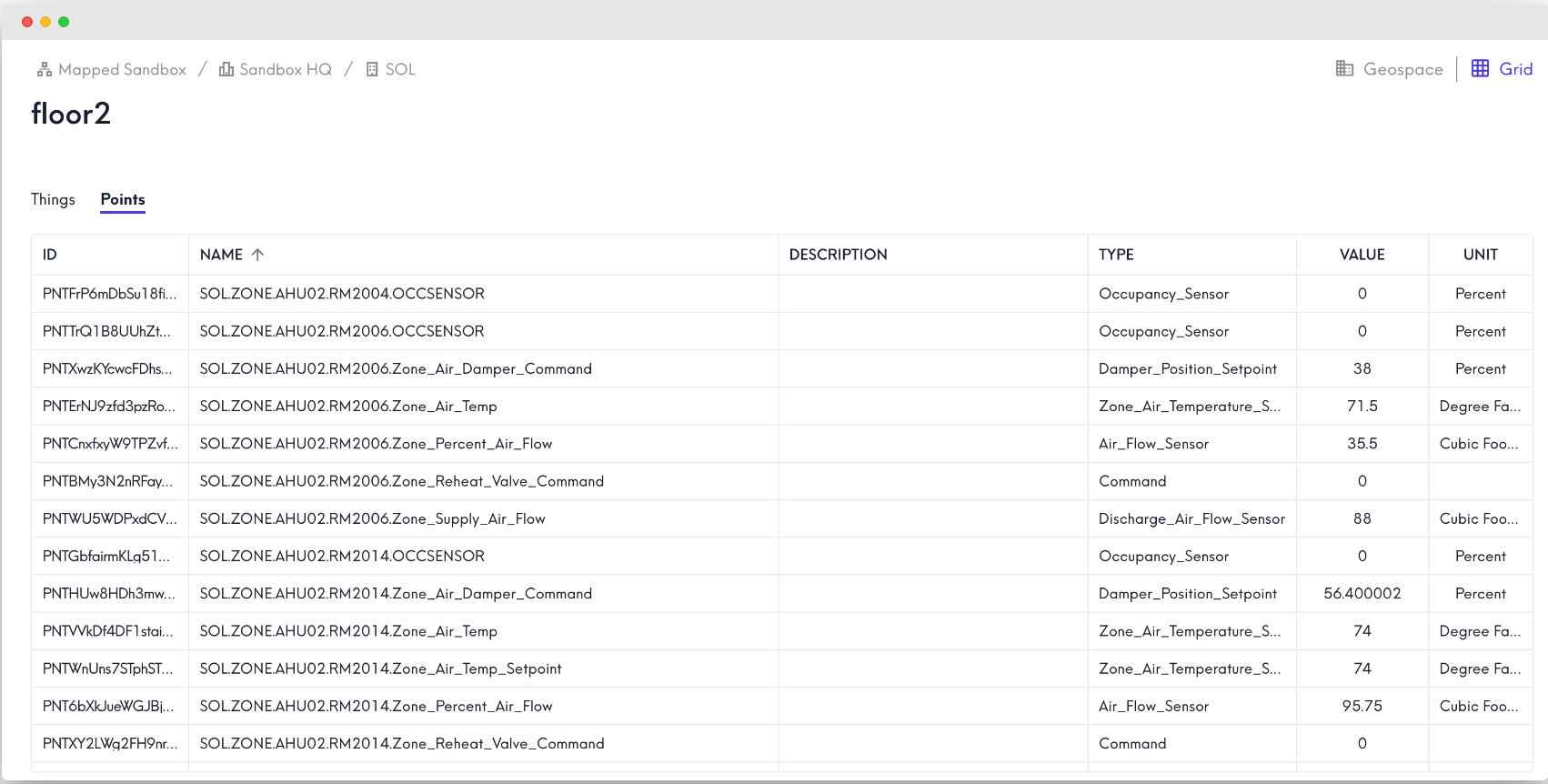
Or a Grid View that shows columns and rows for both Thing and Point data:
After Explore, there's the Connectors tab, which allows you to add various applications like OpenPath and Microsoft Graph to your Mapped organization, expanding your capabilities and opening up new ways to use your data.
You'll also be able to view and configure your Gateways, as well as access the Developer section, where you are now and we'll discuss in detail next.
Mapped for Developers
As a developer, working in IoT can be challenging. Dozens of device protocols, hundreds of vendors, thousand of possible devices - getting everything synced to one spot can take teams of people and weeks of work. We take that effort off your plate by mapping the disparate data streams into one unified GraphQL API with standard data models.
The Mapped API is mostly grouped together in three broad categories: People, Places & Things.
- People represents the individuals that exist in Places (like an office space) and interact with Things (like a badge reader).
- Places represents the physical locations where People and Things exist - buildings, floors on a building, spaces in a floor and so on.
- Things represent devices & equipment inside of a Place, from full HVAC systems to badge readers to individual lights.
What is GraphQL?
GraphQL is an alternative to REST for API development, particularly useful for APIs with large datasets because users can build the structure of a complicated request into a single query. For example, the following GraphQL request retrieves quite a lot of data - it could take up to 100 individual calls to BMS system to achieve the same results, typically to a variety of endpoints:
Request ResponseCopy1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20{ buildings { id name points(filter: {type: {eq: "Temperature_Setpoint"}}) { id name exactType aggregation( startTime: "2024-07-13T17:00:00" endTime: "2024-07-14T17:00:00" period: DAY ) { timestamp avg max } } } }
Here is a summary of what this query will return:
- For the currently authenticated user (or app), return the name and id for each building.
- For each building, filter for all Temperature Set Point sensors.
- For each point, aggregate its time series data for the defined date and time, by the day.
- For each period, return the timestamp along with the average and maximum sensor reading for that period.
For IoT datasets that can be very large and intense, the simplification of GraphQL is clearly beneficial.
How to Make a GraphQL request
GraphQL works similar to REST, in that you'll have a URL to call, headers defined, authentication set and then the body of your request (which would look like the example above). Where it differs - you won't use GET/PUT/POST/DELETE, and you won't use multiple URLs with different endpoints. Here's an example of the specifics needed to make a GraphQL API call:
URL:
- https://api.mapped.com/graphql
- This link will not work in a browser
Headers :
- Authorization: token ABcDZGRpbjpvcGVuc2Vz1138
- Content-type: application/json
- Read the Authentication & Security docs for more info on the Authorization header
Request Body:
Copy1 2 3 4 5 6{ buildings { id name } }
Nearly every doc page has an example request body you can test, but the URL and the headers don't need to change.
Each piece of data returned by the API will contain an opaque string up to 128 characters long - these are static, the ID for any piece of data won't change, and are used extensively in filtering. The format of an ID may vary, so don't include any logic in an app that checks against information like character count; the individual ID for a place or a thing won't change once assigned, however.
Tools to test GraphQL requests:
Insomnia has the benefit of automatically importing our schema via the URL, meaning you can get syntax predictions right in the request body as you type. Postman requires an import of the schema, which takes a bit more effort. Contact Support for help getting that file imported correctly.
In the docs that follow, we will explore all the endpoints you can hit in the API and provide examples to get you going. If you find you have questions that can't be answered in the docs, please reach out to Support anytime.